
Today's cloud data engineering projects require streaming capability. Whether it's IOT data, financial transactions, sms messaging, or MMORPGs, users and business leaders are looking for real time data. In this light we would present a unified streaming architecture which produces a highly structured data stream for modern data lakes.
The goal is to process transactions as quickly and efficiently as possible which enables high throughput data transmissions, processsing, and deposits within your data lake. This is accomplished through a microservices architecture focused on optimzation throughout the entire process chain. Although Apache Airflow is a very good tool for on demand or scheduled execution architecture, it is not suitable for a streaming architecture.
Microservices architecture rely on event driven architecture. Event driven architecture consists of triggers and application logic which coordinate execution pathways. As events fire, such as a user submitting a form, uploading a picture, or placing an order, downstream microservices are triggered and data is processed.
A streaming platform is designed to capture state changes in real time through dependent execution flows. As the data moves through the microservices architecture the state changes are captured and deposited in a data lake or data can be streamed directly into a cloud data warehouse.
A common practice in cloud data engineering is to use an intermediary processor to house and manage event data. Cloud platforms offer messaging services which can collate and proliferate data to multiple sources or endpoints. The data are concentrated and housed in a single collection point which collates multiple streams of data. This is important for data processing efficiency and security as it offers a single point of contact for all of your various applications. In AWS this service is Simple Queue Service and in GCP this is known as PubSub.
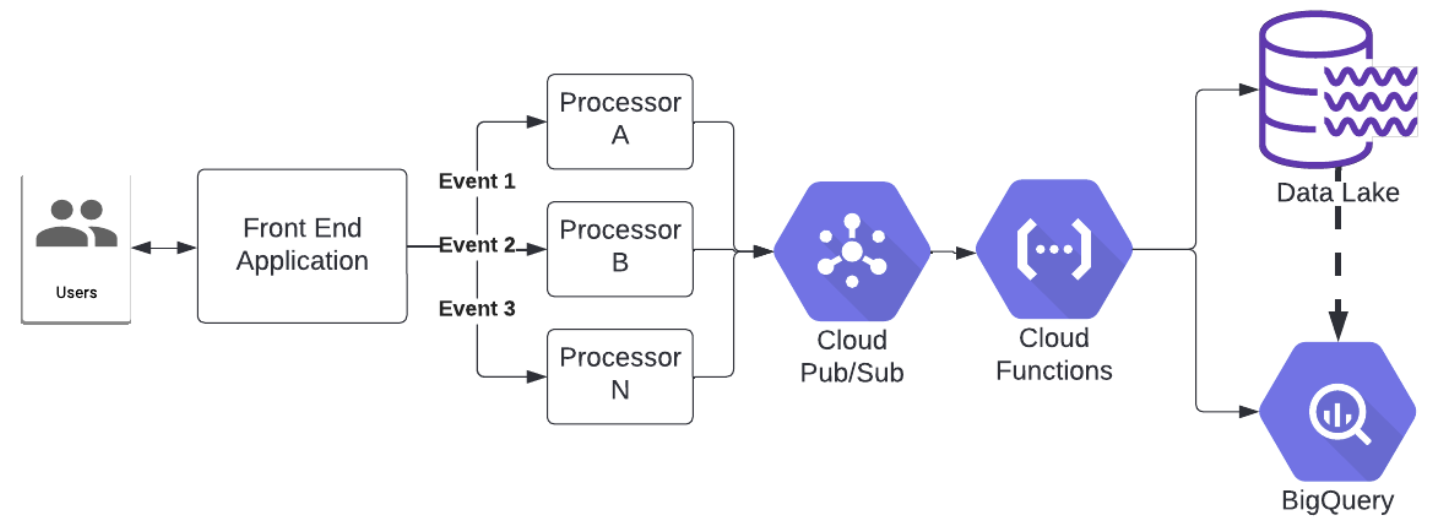
An example streaming data application could consist of an application streaming user transactions (such as eCommerce purchase receipts) into a data lake or into BigQuery directly. It begins with a user making a purchase on a website. As soon as the transaction is completed (payment is received) the data are pushed to a processor. The processor converts the raw data into more useful event data and pushes the data to Cloud PubSub. As soon as the data hits PubSub it is pushed to either Cloud Dataflow or Cloud Functions are spun up in response to the message queue. Dataflow or Cloud Functions would then push the data into cloud storage or stream it directly into BigQuery.
One of the keys to an effective streaming architecture is operational efficiency. The more streamlined and efficient your architecture is the better. Even a few extra wasted milliseconds per transaction could kill your efficiency when multiplied against your entire architecture. Imagine that you have a streaming application processing an average of 100,000 transactions per second (very plausible for larger enterprises). If you waste even 10 extra milliseconds of processing time per transaction that equates to 1,000 seconds/second of wasted processing time. Over the course of a day this becomes 1,000*60*60*24 = 86,400,000 wasted seconds per day! Not only is this inefficient from a performance standpoint, it can also add up to tens of thousands of extra dollars a month in processing fees. For some organizations this could make or break a project's budget.
We encourage the use of managed services when building application architectures. This ensures that you are taking full advantage of cloud provider services. You can rely on the provider conducting regular updates for both performance and security. Additionally, many managed services are optimized to the particular cloud provider's back end architecture which ensures that you maximize the performance of your execution platform. This also frees you up to focus on the application layer and execution logic.