
Data And Metadata
Data and metadata are the lifeblood of all information systems. If data architecture is like a road, then metadata and data are like the vehicles and the passengers. An empty road is useless, but vehicles without a road behave in complete chaos and with no direction.
Modern cloud architectures materialize most objects through two structured text file formats: delimited file formats (CSV, TSV), or as an object notation (such as JSON, Avro, Parquet, etc.) data. Although the data come through essentially as strings (they are text files), the data are parsed via a consistent data schema consisting of proper data types and object structure.
Data Types
Data typing is a method of data classification used to positively identify the nature of your data points. That is, the "kind" of data being examined.
Are we dealing with integers, floats, strings, or something else? Although there can be database specific subtypes of the major types (such as tinyint, long, etc.) we don't consider these relevant when dealing with cloud native data warehouses, such as BigQuery or Redshift, because cloud data warehouse primitive types are almost always sufficient to handle any size of data. Specified subtyping is basically obsolete in cloud warehouses because native typing is satisfactory for all but the rarest use cases. Unless there is a specific reason for using more specific typing, we recommend going with default native types. In the cloud, we are far more focused on optimizing performance and scalability than storage space or usage.
This guide generalizes the data types commonly seen in event data and is not an exhaustive list. For our purposes, we will generalize data types to those listed below. Reference provider specific documentation for specific typing properties within Redshift or BigQuery.
An integer is a simple real whole number.
A float represents a "floating point number" or basically a decimal number. In BigQuery this is also known as a numeric data type.
A string is a set of character data, usually representing ASCII compliant alphanumeric data. This can be anything from a word, to a UUID, or a sentence.
A boolean value is a simple true or false indicator.
JSON data is technically a serialization method to represent objects (schema), but because it is a self-contained "unit of knowledge" it can be considered a data type in certain data warehouses.
Data Schema
Data schema are object models used for translating inbound and representative data into logical concepts of known events. Data schema are mainly used to properly classify and model existent data within a data warehouse. However, in a modern cloud native data stacks this can include the data lake as well. It is important that schemata represent real objects or events which are philosophically sound and logically consistent. Obviously, if your application logic or data capture procedures are flawed then the data will also be flawed.
Event inflows and registration should have proper schemata attached in the form of a conceptualized data model. If schemata are unavailable, or data are not properly typed or divergent (unstructured data, such as NoSQL event data), then it may be necessary to use data parsing procedures which are more adaptable to unstructured or dirty data.
For data engineering purposes we are usually focused on the following schema types:
Structured Data
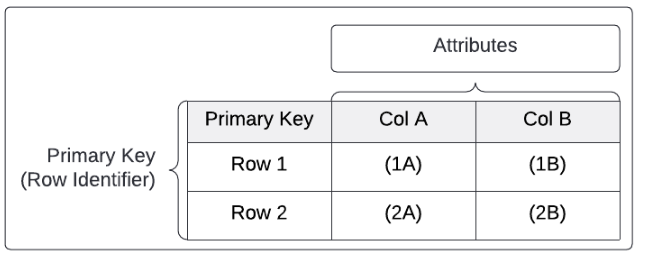
A structured schema consists of two-dimensional data arranged in a series of rows and columns and is commonly referred to tabular data. This is a very common architecture and is often seen in engineering projects, data transmissions, spreadsheet software, and others. This is also the most common data warehousing architecture.
Structured data is often represented within data lakes as delimited files, usually CSV's. Delimited files are universally readable and workable within all cloud data warehouses and are great for working with most data. Structured data can be parsed easily within a cloud data warehouse.
Semi-Structured Data
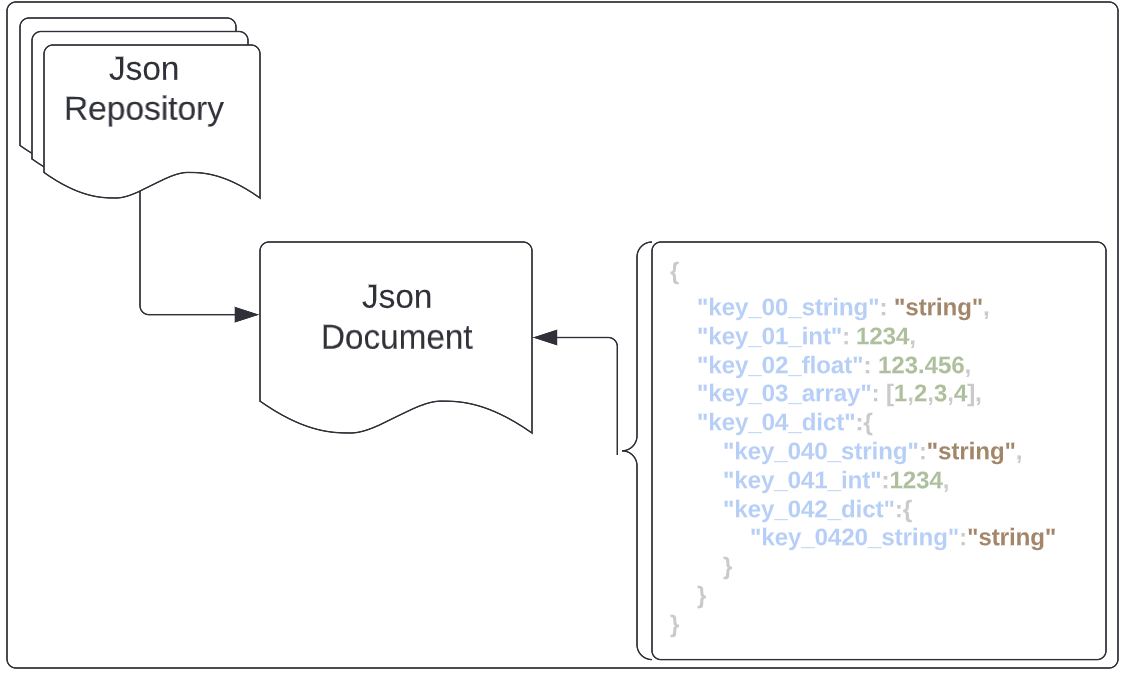
Multidimensional tables are abstract representations of complex dictionary data. These tables are built on top of JSON or Avro data.
There are some notable differences between various cloud data wareouses' approaches to handling semi-structured data. Redshift uses PartiQL to parse complex JSON or semi-structured data whereas BigQuery can use native SQL. In addition, BigQuery has the JSON data type, which provides a sophisticated and SQL native method for working with JSON data. An in-depth comparison of the two methods is beyond the scope of this guide, but we believe that BigQuery's approach is preferable because it can provide complex analytical and parsing structures without having to move between systems.
If the data you are importing is well structured and clean you can use BigQuery's schema auto-detection. However, we've found that this method this can be quite fragile and a single error in the schema detection process or within the data can result in import or query errors, rendering the schema useless.
We can use SQL Native JSON Parsing to create materialized views or tables using native SQL in either Redshift, BigQuery, or any other SQL data warehouse. This method is useful when working with data that may be messy and require data type translation and materialization.