
Transformations
Data transformations are the building blocks of data warehouses. These are the tools which data engineers use to construct complex data structures and pipelines. Data transformations are like the gears of a clock. The gears transform the spring-loaded kinetic energy into movement of the clock's hands around the face. Humans can then translate this into a highly precise understanding of Earth's current facing relative to the sun.
Similarly, data transformations can be thought of as the gears which translate your energy (data) into a useful representation of your business or organizational activity (data warehouse). Transformations are used to shape, clean, transform, and faithfully represent the business facts contained in your data lake. The transformations are used to contain and maintain business logic in every layer of your enterprise data system.
Mathematically, within the context of a data universe, transformations result in augmented vector data which can alter the shape and positioning of your data while maintaining the value of the data contained within. The objective is to maintain proper representation of your data, but to position or reshape the data in a way which is easily and readily consumable by business leaders and organizations.
Transformation Toolbox
Transformations are tools in a toolbox. Much like a horologist's repair kit, we keep a diverse set of tools at our disposal. Since the development and maturation of cloud technology these tools also have evolved to take advantage of the new capabilities afforded. Technologies such as BigQuery or Redshift have given massive data processing capabilities to data engineers which didn't exist even a few years ago, and they are still rapidly advancing and adding more capabilities. It is essential that our tool kit also remains fluid and easily upgradable.
The scale and processing power of the cloud has enabled processing of terabytes of data almost instantly and our toolbox seeks to maximize this potential while also minimizing cost. Many of the transformations involve transforming raw data into structured data sets for use in the data warehouse. To transform text files, including raw and unstructured JSON files, see our data parsing procedures. These procedures take advantage of chained transformations as well as data type transformations to effectively parse and manage metadata and form proper data schemas.
Chained Transformations
Chained Transformations are a useful and efficient method for creating complex and robust transformations within data warehouses. They are highly flexible, general purpose, and functionally complete. These kinds of transformations are prohibitively expensive for most RDBMS's, but with the scalability and computational power of cloud databases these techniques become possible, opening an array of new ETL tactics and calculation methodologies.
This method can be used to create analytical dashboards, ETL operations, or reports. In this case, the purpose of these calculations is to create a final data model with all joins and logic instantiated in the result set itself. These are very useful for building tabulations, dashboards, or calculations which don't require dynamic query plans. When building descendant repeated or record types within BigQuery these techniques prove invaluable.
The concept assumes a given data execution path from start to finish through CTEs or views. All transformations are incorporated as matrix operations by building back to front incremental manipulations on data stored in memory. This has a few advantages over other methods:
- In-memory operations are more efficient and faster than table calculations.
- Complicated and extensive logic can be executed with only one simple command.
- In BigQuery the data only has to be read once regardless of how many times it is operated on. This helps control costs.
- Query plans only need to be created once per modification by the query engine, optimizing query performance.
- The data at each intermediate stage is ephemeral. This is useful when working with sensitive or private data.
- Additionally, it can also help protect intellectual property as any calculations are abstracted away from end users.
Methodology
Chained Transformations are essentially serialized differential equations executed across a common data source. It's important to note that these are best planned front to back, but built back to front. Meaning that you start with the planned solution or model that you are trying to build and then plan backwards how to optimally achieve the solution. Once the plan is materialized you then build each step from back to front. Once all steps are finalized you then execute the final query (usually stored as a view) and retrieve the desired result set or save it to another table.
Begin by constructing the query plan from solution to root nodes. This is formulated by the matrix
transformation representation:
Σx:Nx=> Gx=> Rx=> Px
Where x is the result set from the preceding step and Σx represents the
final
product or result set. The arrows represent matrix transformations from Nx (root node) thru
Σx
(final node)
following vector paths =>. All calculation logic is housed within Gx, Rx, Px, and is executed by
Σx. Gx, Px, Rx, and Σx are all CTEs (linear transformations) which operate on
the data in some way using an incremental method. The final query Σx, assumes all the
logic from the preceding steps. This is usually stored and executed as a view, which
therefore assumes all properties of a view.
By disentangling the logic via incremental transformations, as opposed to attempting to embed multiple transformations within a single query, you can achieve a couple positive effects.
- The transformations are easier to understand, update, and debug.
- It becomes easier to identify and correct bugs or logic errors without having to rebuild the entire query.
- Database engines such as BigQuery's Dremel are able to plan execution lineage more effectively and execute the queries more efficiently without increasing costs.
- The final result set assumes the full logical breadth of the differential while maintaining operational and computational security and integrity.
- Data lineage becomes apparent and documentation is easily materialized when coupled with tools such as dbt or airflow.
Conceptualization
Chained Transformations are encapsulated logic flows which take advantage of embedded logic contained within Common Table Expressions, or CTE's. The CTE's are housed within a conceptualized view. When the view is executed all transformations are executed in sequence and are a priori correct and deterministic.
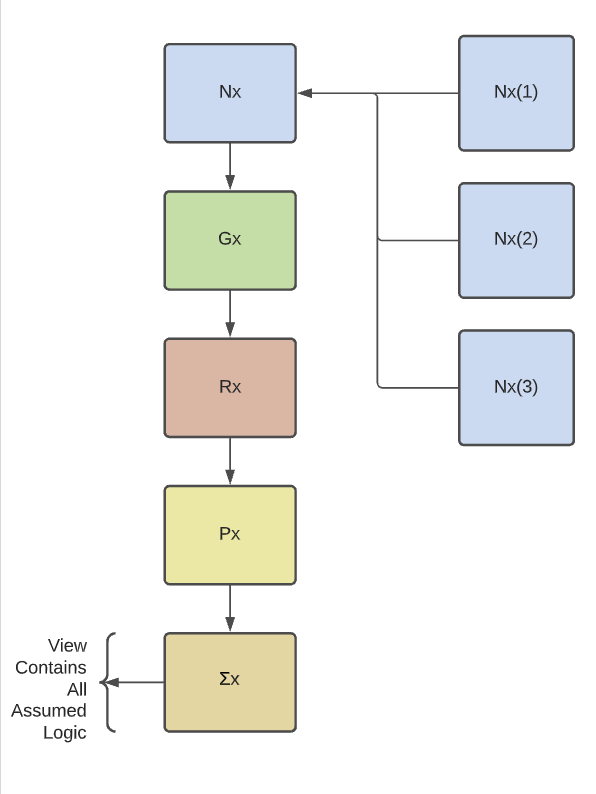
The left-hand image depicts a possible execution flow. The user calls the view using a SELECT statement. This is a SELECT statement FROM Σx. However, what happens is that the query engine plans the path for executing all preceding queries as well. Σx is a SELECT statement FROM Px which is a SELECT statement FROM Rx which is a SELECT statement FROM Gx which is a SELECT statement FROM Nx. Nx is a base query which is a SELECT statement FROM sources Nx(1), Nx(2), AND Nx(3). All of this logic is assumed by simply querying the end view, Σx.
Conceptually the query is planned front to back (Σx to Nx), and then executed back to front (Nx to Σx). The final result set is returned from the original SELECT FROM view statement. At this point the data can be returned as a result set to feed even further analysis, or can be materialized as a table for easy and quick pulling of the end result set.
BigQuery replaces tables as they are recreated. If you execute this query multiple times during a day there will be no discontinuity of data from a user's perspective. The data will change but this will be invisible to the user. This method can be used to append incremental data or execute holistic transformations as well.
Data Type Transformations
Data type transformations are a relatively simple, but very important, set of transformations used when attempting to translate one data type to another. For example, when altering a string value of "$1.25" to a float value of 1.25. This kind of typing is necessary when generating data aggregations in a computationally efficient manner. Data typing and cleaning can take up a lot of time depending upon the quality of the input data. So, having a solid cleaning strategy in place will save you time and improve outcomes.
Given our simplified set of general purpose data types commonly used in data engineering we will establish a set of transformations which will address some common data type transformations used when building your data warehouse or import architecture.
Units of Measurement
Units of measurement are not data types. These are properties of the data element, not the data values, and serve no real purpose when performing mathematical operations on the data. If you have a data column named "net revenue" or "sale price", for example, the unit type (currency), is not a property of the data value, but it is a property of the data column (element). Matematically, this could be considered a constant distributed against the data which can be reintegrated from the individual data values.
Consider a column named "net revenue" which includes the values:
net_revenue = ["$1.25", "$2.34", "$5.67"]The dollar sign is a property of the element "net revenue", and not a property of the value itself. Rename net_revenue to net_revenue_usd which integrates the unit type to the data element. With the dollar sign removed from the values we can now type the values as actual floats which allows for mathematical operations.
net_revenue_usd = [1.25, 2.34, 5.67]Technically, usd is not actually a property of the data column either, but it is instead a property of the actual transaction, however we find that indicating the currency on monteary columns eases readability and facilitates aggregations and visualizations. The same technique could be used with other data types as well. Saying usd instead of $ verifies that we are talking about US dollars and not Canadian. Additionally, this ensures that column names are compliant with your cloud data warehouse column naming conventions.
Data types should be boiled down to their primitive types whenever possible, and any unit identifiers stripped. Typing for unit measures is a conceptualization attached to an indicated value, and is irrelevant when performing calculations against numeric values themselves. Any unit typing should be handled in the presentation layer (such as a visualization tool).
If we attempt numerical operations on the first example above we receive an error.
total_net_revenue_usd = sum(net_revenue)
TypeError: unsupported operand type(s) for +: 'int' and 'str'
The function succeeds when you properly clean and type the data. Note that we then must transform the type of the variable back into a string once more or the print function will fail with the inverse error.
total_net_revenue_usd = sum(net_revenue)
print("$" + str(total_net_revenue_usd))
$9.26
Type Conversion Procedures
Data type conversions are used in data warehousing to convert a data point from one data type to another. In cloud data warehouses nearly all data are transmitted as text files. These are usually delimited files or heirarchical structured data such as JSON. When parsing your data into useful tables within your warehouse you can use data type conversions and other cleaning operations to ensure that your data is well structured and is most efficient for the data warehouse to operate on.
We recommend building a library of common cleaning and typing functions for your data. This ensures continuity among your data models and makes building tables more efficient. Cleaning data always comes first, and is necessary to effectively type your data. These operations can become very complex depending upon how dirty or unstructured your data is.
An easy way to identify unclean data is to use WHERE <column> IS NOT NULL AND SAFE_CAST(<column> AS <data_type>) IS NULL clause when examining your data for errors. SAFE_CAST can isolate any data points which are not typed correctly. After you have identified any malformed or dirty data you can then devise SQL patters which clean and type the data correctly. You should always clean the data in order to ensure that data typing will succeed.